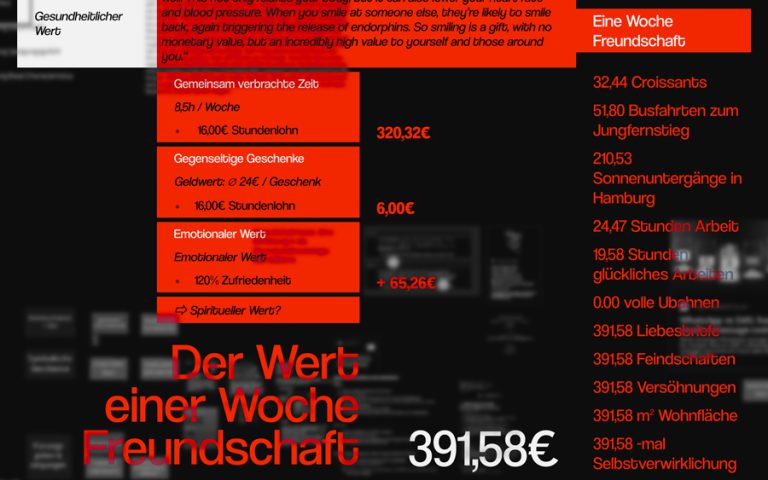
«It used to be that when you communicated with someone the person you were communicating with was as important as the information. Now on the internet, the person isn’t important at all.» – Lawrence Krauss Das Netz ist voller Informationen, was nicht zwingend etwas Schlechtes ist. Das bringt aber natürlich auch Probleme mit sich: Information is not knowledge – man kann sich auf die Richtigkeit von Informationen im Netz nicht so ohne Weiteres verlassen.…
«It used to be that when you communicated with someone the person you were communicating with was as important as the information. Now on the internet, the person isn’t important at all.» – Lawrence Krauss
Das Netz ist voller Informationen, was nicht zwingend etwas Schlechtes ist. Das bringt aber natürlich auch Probleme mit sich: Information is not knowledge – man kann sich auf die Richtigkeit von Informationen im Netz nicht so ohne Weiteres verlassen. Im Kurs «On Becoming A Filter» haben wir uns in diesen Ecken des Netzes rumgetrieben. Da, wo das Potenzial im Rabbithole verloren zu gehen, extrem groß ist. Wir nutzen die Chance, eine einigermaßen große Gruppe zu sein, um Wissen zu sammeln, aufzubereiten, in Form und vor allem ins Web zu bringen. Wir müssen also einen Umgang mit diesem Problem finden.
Lawrence Krauss sagt, wir müssen unser eigener Filter werden, um die Richtigkeit und Relevanz von Informationen im Web zu kontrollieren, denn dieser wird mit der Information nicht mitgeliefert. Cool, aber wie wird man sein eigener Filter? Vielleicht ja, in dem wir uns selber – als Person mit dem, was uns interessiert und was wir erlebt haben – zwischen die Information und ihre (mögliche) Un-/Richtigkeit stellen. Das meint nicht, dass wir plötzlich allem gegenüber unkritisch sein dürfen und alles erlaubt ist. Das meint vor dem Hintergrund einer Sammlung viel eher, dass es eine Ebene erfahrungsbasierten, scheinbar beiläufigen Wissens gibt. Nur mit diesem impliziten Wissen, ist auch die Sammlung kohärent.
Eine Webseite bauen kann heute jede*r. Irgendwo schnell einen Account machen, die Liste an verfügbaren Templates nach free filtern und in null Komma nichts hat man eine Seite. Zugegeben, das ist eine sehr designferne Perspektive – und eher der Worst Case. Aber selbst wenn man sich selber aus diesem Sumpf ziehen möchte, sich ein bisschen HTML, CSS und vielleicht Javascript beibringt, sind die Tools und Seiten, mit und auf denen man genau das tun kann, oftmals Sandboxes – also hermetisch abgeriegelte Umgebungen. Das ist für das Erlernen der Basics zwar sinnvoll, aber wie aus meinen HTML- und CSS-Dateien dann eine richtige Seite im richtigen Web wird, weiß ich dann immer noch nicht.
Was also für viele bleibt ist die Frage: What’s a website, anyway?
www.hyper–link.me